
Robot Perception

Aerial Human MoCap: Real image sequence (top left). Estimated 3D pose and shape (top right). Two of our aerial robots cooperatively detecting and tracking a person (bottom). Overlaid pose results (bottom middle). Reinforcement Learning based human MoCap (bottom right).
In this research area, we investigate new methods to fuse measurements obtained from various on-board sensors of a robot, and those obtained from communication with other robots in the team, to estimate the state of the environment. Sensors in our case primarily include on-board cameras -- the vision sensors. Other sensors include IMUs, event cameras, air-speed sensor, etc. State of the environment includes positions and poses of subjects such as humans, animals and other robots, as well as the map of the static part of the environment.
Our first pillar of work in the context of Robot Perception is Motion Capture, or MoCap. It means estimation of the trajectory of 3D poses and shape of a human or animal over time. Pose here means the skeletal position (position of major joints in 3D space), and shape can be visualized as a mesh of vertices on the subject's body. Our core interest in this context is to study and develop vision-based methods for both animal and human MoCap in outdoor, unknown and unstructured environments. These include, for example, wild animals in their natural habitat.
Our second pillar of work in the context of Robot Perception is Simultaneous Localization and Mapping, or SLAM. SLAM is one of the most fundamental and classical topics in robotics. What is unique in our group is that we study SLAM from the lens of combining perception with action -- which in literature is referred as 'active SLAM'. Here we e focus on both novel methodological (algorithmic) and system-focused (new robot designs) approaches for active SLAM.
Aerial Human Motion Capture (MoCap)

We have developed various methods for human MoCap from aerial images acquired simultaneously from multiple aerial robots. The methods range from optimization based to end-to-end learning based. Typically we employ 2D joint detectors that provide measurements of joints on images. A body model, learned using large number of human body scans is used as a prior to predict the measurements, assuming arbitrary camera extrinsics. Thereafter, the body model parameters and the camera extrinsics are jointly optimized to explain the 2D measurements in the least squares sense. The end-to-end method learns to directly predict the body model parameters using as input only the images from an aerial robot and compact measurements communicated to it from its teammates. We have also developed methods for real-time execution of these MoCap methods on the aerial robot's on-board computer. In a much recent work, we have developed an optimization-based method to perform human MoCap from multiple static and moving extrinsically uncalibrated RGB cameras. In this work, we learn a probability distribution of short human motion sequences (~1 sec) relative to the ground plane and leverage it to disambiguate between the camera and human motion. We further use this distribution as a motion prior in a novel multi-stage optimization approach to fit the SMPL human body model and the camera poses to the human body keypoints on the images and eventually we show that our method can work on a variety of datasets ranging from aerial cameras to smartphones. Figure: Our aerial robots performing human MoCap. Pose trajectory of the human (displayed on the right), estimated by the robot (on the left).
Aerial Animal Motion Capture (MoCap)

Visual methods for estimating animal pose and shape are a key part of an aerial animal MoCap system. While considerable progress has been achieved in human pose and shape estimation, existing methods for animals are insufficient for two primary reasons. First, there are hardly any methods that perform pose estimation using several simultaneous views on an animal animal in motion. This requirement contributes to reliable pose estimation and lays the ground for studying contact, interaction and estimating reliable shape. Second, acquiring data for training animal models presents a challenge, given animals are less cooperative than humans and are difficult to observe in their natural habitats. We argue, however, that creating a dataset with reliable animal shapes and poses is of great importance, since it would allow for extending existing methods developed for human pose estimation to animals.
To address these challenges, we have collected a significant amount of visual data of Grévy's zebras and Przewalski's horses using our aerial robots (UAVs). Using on-board high resolution cameras
of these robots and taking advantage of their mobility, we have acquired hundreds of hours of high quality multi-view video sequences. The footage was collected over several seasons in different
lighting conditions and in different locations. We have developed a pipeline to synchronize these videos, as well as to perform semi-automated data annotation and pre-processing. We have also
done high-level manual annotations of these videos. After synchronization, we performed semi-automated bounding box annotation. We then used a combination of feature detectors, which allowed us
to estimate 2D keypoints on each frame. Finally, we have developed an articulated multi-view pose estimation method based on optimization, leveraging the SMALR model. We are able to improve the
fitting accuracy compared to the previous methods. The code and dataset of this ongoing work is available. In addition, we achieved an improvement in fitting speed by creating our own PyTorch
implementation of the algorithm. Figure: Aerial Animal MoCap: Grévy's zebra in Wilhelma zoo (top right and bottom). Results of our optimization-based
multi-view animal motion capture method (top-left).
Aerial Perception

Detecting and tracking 3D positions of subjects (humans or animals) from air, i.e, using micro aerial vehicles (MAVs) is a challenging problem, especially due to limited on-board computation capabilities of such vehicles/robots. On the other hand, state-of-the-art deep neural network (DNN) based methods can solve a number of perception problems like detection, classification and identification. Such DNNs are not only computation-hungry but also often fail to detect people that appear very small in images, which is typical in scenarios with aerial robots. In one of our works, we have developed novel DNN-based methods that can be deployed on small computing hardware suitable for aerial platforms, and can run on-board and in real-time. To this end, our methods leverage communication between multiple aerial robots as well as contextual knowledge such as mutual observation of the same target. Figure: Cooperative detector and tracker's selection of the most informative regions of the images from each of the two aerial robots (top row). Rviz state estimates of the aerial robots (bottom left). The moment of the image capture by the two aerial robots (bottom right).
Active Visual Simultaneous Localization and Mapping (Active V-SLAM)

In this context, we have focused on developing methods active SLAM methods that could allow a robot to efficiently and autonomously explore an environment. One of our key contributions in a recent work is a multi-layered approach that works by optimizing the robot's heading in both the global and local scales. The method, called 'iRotate', was firstly developed for our omnidirectional robots (see Figure) in our work and resulted in exploration paths up to 39% shorter than the state-of-the-art approaches. To expand iRotate to semi and non-holonomic platforms, we developed a custom camera's independent rotational joint. This also further lowered energy consumption by reducing the rotation of the wheels, thanks to a more flexible control. The proposed joint state estimation also proved its efficacy by lowering the trajectory error of up to 40--50%. Currently, to expand this work, we are generating a dataset of indoor dynamic environments to move toward more realistic scenarios. Figure: Active Visual SLAM: Our novel ground robots performing active SLAM.
Cooperative Perception in Multi-Robot systems
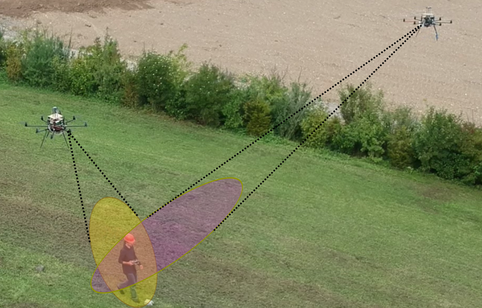
Fusion of information among robots/agents in a team is fundamental for a coherent understanding of the environment and, consequently, for reliable decision making as a team. In this regard, we investigate and develop a range of methods for cooperative target tracking, cooperative localization of robots as well as unified methods for performing tracking and localization simultaneously. Furthermore, we also investigate cooperative human and animal pose estimation methods. Our methods include both parametric (EKF) and non-parametric (Particle Filters) approaches. Figure: Two of our aerial robots cooperatively tracking a human in motion.